文章详情页
网页爬虫 - 关于python beautifullsoup解析网页内容丢失的问题?
浏览:223日期:2022-09-23 08:23:07
问题描述

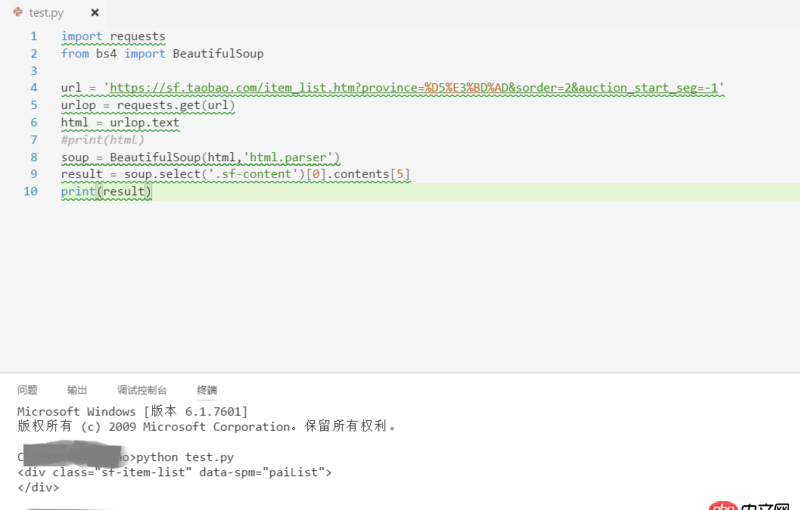
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~
问题解答
回答1:你们从来都不考虑javascript动态加载的吗?
回答2:题主,如果你用Chrome F12看的话,里面是会有动态加载的内容的,而这些内容你直接请求页面的url是拿不到的。建议你点右键查看网页源代码,对照着F12里面的内容来看,源代码里没有的内容,就去查看Network里的其他请求,看有没有你需要的数据。
相关文章:
1. Docker for Mac 创建的dnsmasq容器连不上/不工作的问题2. objective-c - 使用axios 通过vuex mutation修改数据 getter第一次获取失败 第二次成功3. javascript - 使用angular给图片动态赋值src属性出现unsafe的情况4. javascript - chart.js如何修改某个指定bar的颜色5. 请教使用PDO连接MSSQL数据库插入是乱码问题?6. docker镜像push报错7. 关docker hub上有些镜像的tag被标记““This image has vulnerabilities””8. node.js - 我是一个做前端的,求教如何学习vue,node等js引擎?9. docker - 如何修改运行中容器的配置10. Python如何利用Selenium或者PhantomJS爬取动态网页内容
排行榜
 网公网安备
网公网安备