文章详情页
网页爬虫 - Python:爬虫的中文编码问题?
浏览:307日期:2022-08-26 10:56:16
问题描述
爬取中文网页后正则匹配出中文,得打UTF-8的编码字符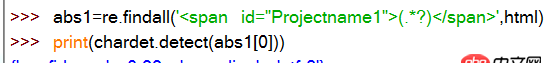
将其输出为.csv文件
在.CSV中显示为乱码
用记事本打开.csv又可以正常显示为中文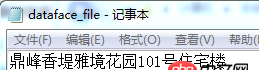
有没有大神指点是怎么一回事?怎样才能在Excel里直接看到中文?
问题解答
回答1:简单地方法是用pandas的to_excel方法转化成.xlsx文件,因为.xlsx默认编码是默认支持Excel的,区别当然是无法用记事本打开。
import pandas as pda = pd.read_csv(’./test.csv’)a.to_excel(’./test_output.xlsx’, index=False)a.to_excel(’./test_output.csv’, index=False)
我这里没有windows可以测试,可以尝试写入编码为gb2312或者gbk试试。
表格文件类I/O的话其实pandas更方便一点。
回答2:abs1=abs1.decode().encode(’gbk’)
回答3:excel默认使用的是GBK编码。
回答4:新建一个excel文件,然后点 数据 自文本,导入csv文件
相关文章:
1. 如何解决docker宿主机无法访问容器中的服务?2. javascript - webpack构建工具重构代码的流程是怎么样的?3. java - 安卓调用c++lib4. javascript - 想做一个canvas的触摸画板,但屏幕会在画的时候滚来滚去,如何阻止?5. mysql 5个left关键 然后再用搜索条件 几千条数据就会卡,如何解决呢6. java - 使用 RedisTemplate 操作数据7. java - tomcat部署启动项目后报错 请大神帮我看一下8. css - 如何讓圖片像雲一樣的行為?9. javascript - 如何根据package.json来自动安装包10. mysql - sql 左连接结果union右连接结果,导致重复性计算怎么解决?
排行榜
 网公网安备
网公网安备