Python多进程multiprocessing、进程池用法实例分析
本文实例讲述了Python多进程multiprocessing、进程池用法。分享给大家供大家参考,具体如下:
内容相关:multiprocessing:
进程的创建与运行 进程常用相关函数进程池:
为什么要有进程池 进程池的创建与运行:串行、并行 回调函数多进程multiprocessing:python中的多进程需要使用multiprocessing模块
多进程的创建与运行:1.进程的创建:进程对象=multiprocessing.Process(target=函数名,args=(参数,))【补充,由于args是一个元组,单个参数时要加“,”】
2.进程的运行: 进程对象.start()
进程的join跟线程的join一样,意义是 “阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程”
注:在windows中代码中必须使用这个 ,在Linux 中不需要加这个
,在Linux 中不需要加这个
import multiprocessing,time,osdef thread_run(): print(threading.current_thread())def run(name): time.sleep(1) print('hello',name,'run in ',os.getpid(),'ppid:',os.getppid())if __name__==’__main__’:#必须加 obj=[] for i in range(10): p=multiprocessing.Process(target=run,args=(’bob’,)) obj.append(p) p.start() start_time=time.time() for i in obj: i.join() print('run in main') print('spend time :',time.time()-start_time) 与多线程同样的:也可以通过继承multiprocessing的Process来创建进程
继承multiprocessing的Process类的类要主要做两件事:
1.如果初始化自己的变量,则先要调用父类的__init__()【如果不调用,则要自己填写相关的参数,麻烦!】然后做自己的初始化;如果不需要初始化自己的变量,那么不需要重写__init__,直接使用父类的__init__即可【已经继承了】
2.重写run函数
import multiprocessingclass myProcess(multiprocessing.Process): def run(self): print('run in myProcess')if __name__=='__main__': p=myProcess() p.start() p.join()进程常用相关函数: os.getpid():获取当前进程号。 os.getppid():获取当前进程的父进程号。 进程对象.is_alive():判断进程是否存活

from multiprocessing import Poolimport time,osdef func1(i): time.sleep(1) print('run in process:',os.getpid())if __name__=='__main__': pool=Pool(5) start_time = time.time() for i in range(10): pool.apply(func=func1,args=(i,))#串行,这里是加一个运行完再加一个 pool.close()#先close再等待 pool.join() print('main run done,spend_time:',time.time()-start_time) 并行:进程池对象.apply_async(func=函数名,args=(参数,),callback=回调函数)
from multiprocessing import Poolimport time,osdef func1(i): time.sleep(1) print('run in process:',os.getpid())if __name__=='__main__': pool=Pool(5) start_time = time.time() for i in range(10): pool.apply_async(func=func1,args=(i,))#并行 pool.close()#先close再等待 pool.join() print('main run done,spend_time:',time.time()-start_time)#2.6,证明是并行回调函数的使用:在并行中,支持callback=回调函数,当一个进程执行完毕后会调用该回调函数,并且参数为func中的返回值 注意:回调函数是在父进程中执行的!【当儿子执行完后,会在父亲里调用函数】
from multiprocessing import Poolimport time,osdef func1(i): time.sleep(1) print('run in process:',os.getpid()) return 'filename'def log(arg):##参数为进程创建中func的函数的返回值 print('log done :',arg)if __name__=='__main__': pool=Pool(5) start_time = time.time() for i in range(10): pool.apply_async(func=func1,args=(i,),callback=log,)#log的参数是func1的返回值 pool.close()#先close再等待 pool.join() print('main run done,spend_time:',time.time()-start_time)
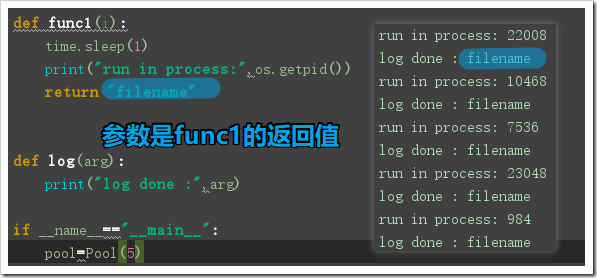
 小测试:
小测试:
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python进程与线程操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》、《Python+MySQL数据库程序设计入门教程》及《Python常见数据库操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关文章:
 网公网安备
网公网安备