Python 处理带有 u 的字符串操作
最近遇到一个头疼的问题,用socket接收到一个字符串
格式如下:{“trade_status”: {“desc”: “u30106u3011 - u8d22u52a1u7ed3u7b97u5df2u5b8cu6210 “}}/end/
其中含有一段含有u的编码字串,怎么将其转化为汉字。
decode().encode(‘utf-8’) 不行,decode、encode半天搞不定,后来偶然发现,在decode时可以选则unicode-escape
代码如下:# -*- coding: utf-8 -*-import socketif __name__ == ’__main__’: sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.connect((’192.168.6.63’, 10001)) sock.send(’[{'action': 'trade_status'}]’) rec = sock.recv(1024) print rec print rec.decode(’unicode-escape’).encode(’utf-8’) print rec.decode(’raw_unicode-escape’).encode(’utf-8’) sock.close()输出结果:
{'trade_status': {'desc': 'u30101u3011 - u4ea4u6613u4e2d '}}/**end**/{'trade_status': {'desc': '【1】 - 交易中 '}}/**end**/{'trade_status': {'desc': '【1】 - 交易中 '}}/**end**/
补充:Python3解析【u】和【u】字符
【u】字符示例a = ’u5317u4eacu5e02’print(a)
北京市
b = ’u5317u4eacu5e02’print(b)
u5317u4eacu5e02
json.loads解析import jsona = ’u5317u4eacu5e02’b = ’'%s'’ % ac = json.loads(b)print(a, b, c, sep=’n’)
u5317u4eacu5e02
“u5317u4eacu5e02”
北京市
读取文件中u字符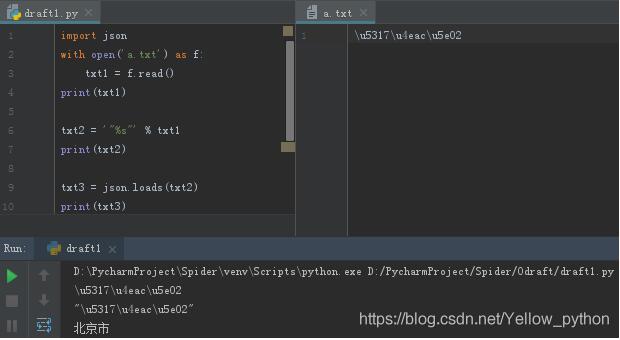
from demjson import decode # pip install demjson
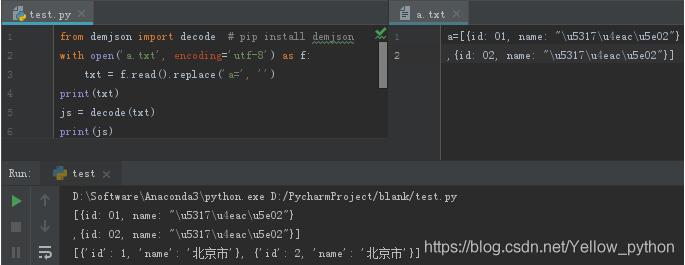
以上为个人经验,希望能给大家一个参考,也希望大家多多支持好吧啦网。如有错误或未考虑完全的地方,望不吝赐教。
相关文章:

 网公网安备
网公网安备