Python统计文本词汇出现次数的实例代码
问题描述
有时在遇到一个文本需要统计文本内词汇的次数 的时候 ,可以用一个简单的python程序来实现。
解决方案
首先需要的是一个文本文件(.txt)格式(文本内词汇以空格分隔),因为需要的是一个程序,所以要考虑如何将文件打开而不是采用复制粘贴的方式。这时就要用到open()的方式来打开文档,然后通过read()读取其中内容,再将词汇作为key,出现次数作为values存入字典。
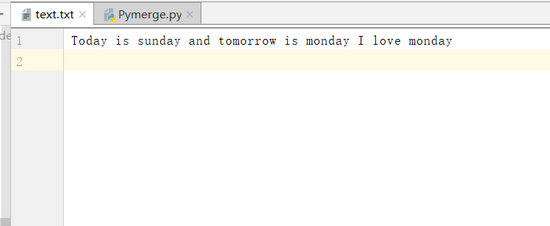
图 1 txt文件内容
再通过open和read函数来读取文件:
open_file=open('text.txt')file_txt=open_file.read()
然后再创建一个空字典,将所有出现的每个词汇作为key保存到字典中,对文本从开始到结束,循环处理每个词汇,并将词汇设置为一个字典的key,将其value设置为1,如果已经存在该词汇的key,说明该词汇已经使用过,就将value累积加1。
代码示例:
def wordcount(readtxt):readlist = readtxt.split()dict1={}for every_world in readlist:if every_world in dict1:dict1[every_world] += 1else:dict1[every_world] = 1return dict1print(wordcount(file_txt))
这里加了def函数把该程序封装成一个函数。 最后输出得到词汇出现的字典:
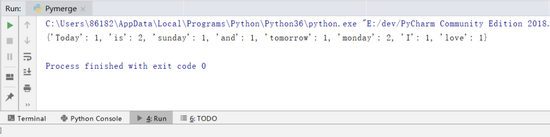
图 2 形成字典
ps:下面看下python统计文本中每个单词出现的次数
1.python统计文本中每个单词出现的次数:
#coding=utf-8__author__ = ’zcg’import collectionsimport oswith open(’abc.txt’) as file1:#打开文本文件 str1=file1.read().split(’ ’)#将文章按照空格划分开print '原文本:n %s'% str1print 'n各单词出现的次数:n %s' % collections.Counter(str1)print collections.Counter(str1)[’a’]#以字典的形式存储,每个字符对应的键值就是在文本中出现的次数
2.python编写生成序列化:
__author__ = ’zcg’#endcoding utf-8import string,randomfield=string.letters+string.digitsdef getRandom(): return ''.join(random.sample(field,4))def concatenate(group): return '-'.join([getRandom() for i in range(group)])def generate(n): return [concatenate(4) for i in range(n)]if __name__ ==’__main__’: print generate(10)
3.遍历excel表格中的所有数据:
__author__ = ’Administrator’import xlrdworkbook = xlrd.open_workbook(’config.xlsx’)print 'There are {} sheets in the workbook'.format(workbook.nsheets)for booksheet in workbook.sheets(): for col in xrange(booksheet.ncols): for row in xrange(booksheet.nrows): value=booksheet.cell(row,col).value print value
其中xlrd需要百度下载导入这个模块到python中
4.将表格中的数据整理成lua类型的一个格式
#coding=utf-8__author__ = ’zcg’#2017 9/26import xlrdfileOutput = open(’Configs.lua’,’w’)writeData='--@author:zcgnnn'workbook = xlrd.open_workbook(’config.xlsx’)print 'There are {} sheets in the workbook'.format(workbook.nsheets)for booksheet in workbook.sheets(): writeData = writeData+’AT’ +booksheet.name+’ ={n’ for col in xrange(booksheet.ncols): for row in xrange(booksheet.nrows): value = booksheet.cell(row,col).value if row ==0: writeData = writeData+’t’+’['’+value+’']’+’=’+’{’ else: writeData=writeData+’'’+str(booksheet.cell(row,col).value)+’', ’ else: writeData=writeData+’},n’ else: writeData=writeData+’}nn’else : fileOutput.write(writeData)fileOutput.close()
总结
到此这篇关于Python统计文本词汇出现次数的实例代码的文章就介绍到这了,更多相关Python统计文本词汇出现次数内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:

 网公网安备
网公网安备