python - 如何爬取豆瓣电影的详细信息
问题描述
我想爬取每个电影的制片国家地区,但是它上面并不在一个标签里面应该怎么办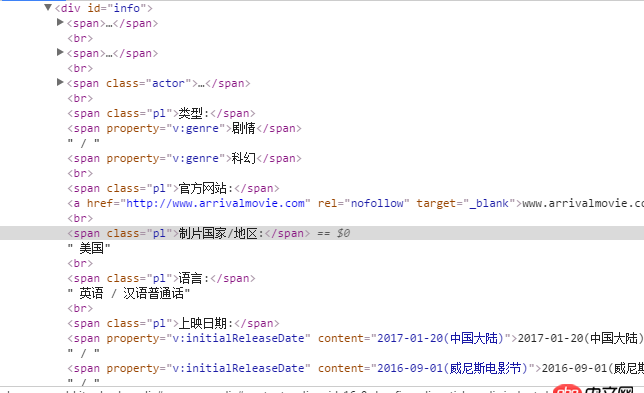 我用的是request和BeautifulSoup
我用的是request和BeautifulSoup
res2=requests.get(h2)res2.encoding=’utf-8’soup2=BeautifulSoup(res2.text)
这部分是已经获取该网页
问题解答
回答1:参考以下代码:
#!/usr/bin/env python# -*- coding:utf-8 -*-import reimport requestsfrom bs4 import BeautifulSoupresult = requests.get(’https://movie.douban.com/subject/3541415/’)result.encoding = ’utf-8’soup = BeautifulSoup(result.text, ’html.parser’)try: info = soup.select(’#info’)[0] print re.findall(ur’(?<=制片国家/地区: ).+?(?=n)’, info.text)[0]except Exception, e: print e回答2:
正则匹配</span>和<br>之间的内容。
回答3:1、可以用正则
2、建议用soup.find_all看文档
https://www.crummy.com/softwa...
soup.find_all('title')# [<title>The Dormouse’s story</title>]soup.find_all('p', 'title')# [<p class='title'><b>The Dormouse’s story</b></p>]soup.find_all('a')# [<a href='http://example.com/elsie' id='link1'>Elsie</a>,# <a href='http://example.com/lacie' id='link2'>Lacie</a>,# <a href='http://example.com/tillie' id='link3'>Tillie</a>]soup.find_all(id='link2')# [<a href='http://example.com/lacie' id='link2'>Lacie</a>]
黄哥Python 回答
相关文章:
1. docker gitlab 如何git clone?2. 利用百度地图API定位及附件商家信息服务3. java比较时间4. javascript - 关于iscroll的一段代码,希望有人解释5. mysql - 一个sql的问题6. Browser-sync安装失败问题7. python - celery beat 调度如何运行期间动态添加任务?8. android-webview - Android 7.0 webview不自动刷新9. Python如何利用Selenium或者PhantomJS爬取动态网页内容10. 网站建设 - 如何在基于nginx上搭建的wordpress中自定义文件夹和网页文件?

 网公网安备
网公网安备