文章详情页
网页爬虫 - Python爬虫返回状态码与实际情况不符?
浏览:336日期:2022-09-03 18:57:11
问题描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如这个爬虫,输出状态码是200。

可是直接访问http://www.sxxrcs.com/was5/web/是404,抓包响应的也是404,请问这是为什么?
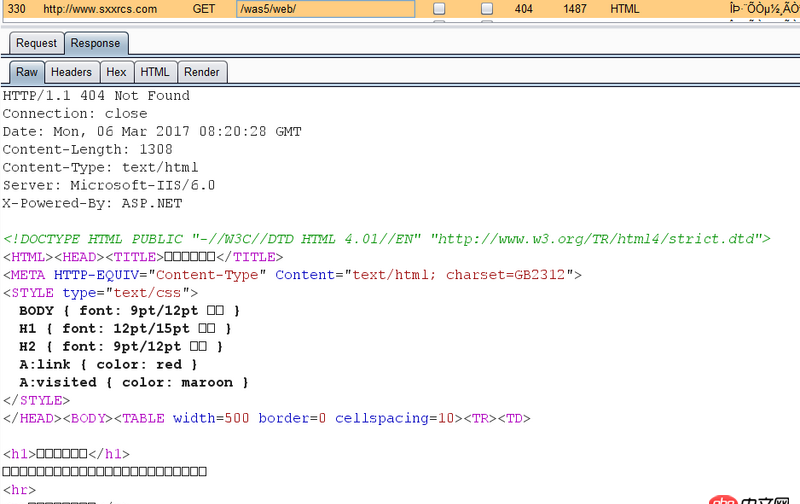
问题解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相关文章:
1. docker网络端口映射,没有方便点的操作方法么?2. docker api 开发的端口怎么获取?3. Docker for Mac 创建的dnsmasq容器连不上/不工作的问题4. docker容器呢SSH为什么连不通呢?5. 前端 - 类到底该如何去命名 .newsList 这种的命名难道真的不是过度语义化吗?~6. docker gitlab 如何git clone?7. 如何解决Centos下Docker服务启动无响应,且输入docker命令无响应?8. 请问“由于 Cookie “PHPSESSID”的“SameSite”属性设置为“None”,但缺少“Secure”属性,此 Cookie 未来将被拒绝。”请问出现这个问题怎么办?9. docker images显示的镜像过多,狗眼被亮瞎了,怎么办?10. Hbuilder中的phpMyAdmin访问题
排行榜

 网公网安备
网公网安备