文章详情页
python - scrapy运行爬虫一打开就关闭了没有爬取到数据是什么原因
浏览:158日期:2022-08-05 15:09:38
问题描述
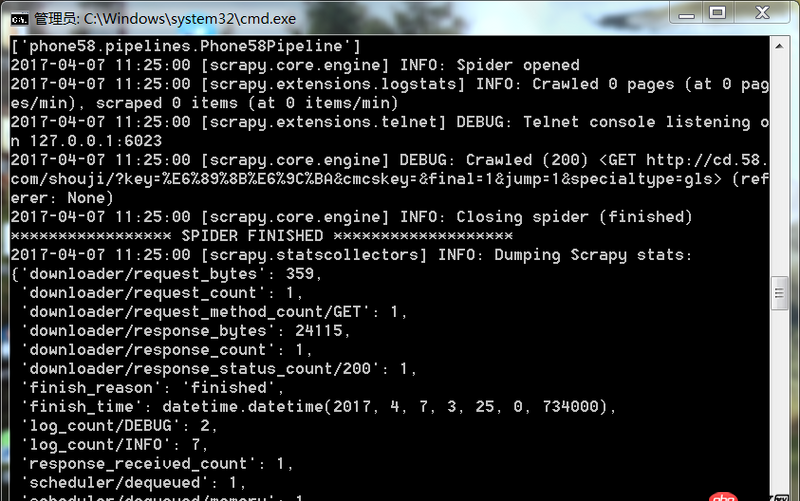
爬虫运行遇到如此问题要怎么解决
问题解答
回答1:很可能是你的爬取规则出错,也就是说你的spider代码里面的xpath(或者其他解析工具)的规则错误。导致没爬取到。你可以把网址print出来,看看是不是[]
相关文章:
排行榜
问题描述
爬虫运行遇到如此问题要怎么解决
问题解答
回答1:很可能是你的爬取规则出错,也就是说你的spider代码里面的xpath(或者其他解析工具)的规则错误。导致没爬取到。你可以把网址print出来,看看是不是[]
相关文章:
 网公网安备 34170202000408号-皖ICP备2020019022号-1 sitemap
网公网安备 34170202000408号-皖ICP备2020019022号-1 sitemap
Copyright ¢ 2020-2025 Powered by http://www.haobala.com V1.8 All Rights Reserved 技术支持:好吧啦网