Python爬虫的乱码问题?
问题描述
使用python实现模拟登陆并爬取返回页面的时候出现了乱码,目标网页的编码使用utf-8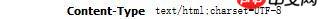
相关代码:
#coding=utf-8import urllibimport urllib2headers={ ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’, ’Accept-Encoding’:’gzip, deflate’, ’Accept-Language’:’zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3’, ’Connection’:’keep-alive’, ’User-Agent’:’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36’}payload={ ’_eventId’:’submit’, ’lt’:’_cF2A0EB3F-D044-046C-6F4A-C828DE0ACE8E_k8B4BE5F5-4CAD-375D-0DDC-FB84A18445DF’, ’password’:’’, ’submit’:’登 录’, ’username’:’’}payload=urllib.urlencode(payload)request = urllib2.Request(posturl, payload, headers)print requestresponse = urllib2.urlopen(request)text = response.read()print text
控制台输出信息:
第一次遇见这种乱码比较懵逼
问题解答
回答1:urllib2没有处理压缩的问题,你要使用gzip解压,比如这样
from StringIO import StringIOimport gzipif response.info().get(’Content-Encoding’) == ’gzip’: buf = StringIO(text) f = gzip.GzipFile(fileobj=buf) data = f.read()
总结urllib2比较底层,建议使用requests
相关文章:
1. docker images显示的镜像过多,狗眼被亮瞎了,怎么办?2. docker容器呢SSH为什么连不通呢?3. docker api 开发的端口怎么获取?4. 如何解决Centos下Docker服务启动无响应,且输入docker命令无响应?5. docker start -a dockername 老是卡住,什么情况?6. 请问“由于 Cookie “PHPSESSID”的“SameSite”属性设置为“None”,但缺少“Secure”属性,此 Cookie 未来将被拒绝。”请问出现这个问题怎么办?7. docker网络端口映射,没有方便点的操作方法么?8. Docker for Mac 创建的dnsmasq容器连不上/不工作的问题9. golang - 用IDE看docker源码时的小问题10. 前端 - 类到底该如何去命名 .newsList 这种的命名难道真的不是过度语义化吗?~

 网公网安备
网公网安备