Python爬虫如何爬取span和span中间的内容并分别存入字典里?
问题描述
我想把房屋概况分别抓出来并分别作为独立的列存储进字典里,但是行内元素没有办法直接用for循环抠出来。这是我的代码:
soup.select(’.house-info li’)[1].text.strip()
这是网页html代码:
<li><span class='info-tit'>房屋概况:</span>住宅<span class='splitline'>|</span>1室1厅1卫<span class='splitline'>|</span><span>46m²</span><span class='splitline'>|</span> (高层)/共18层<span class='splitline'>|</span>南北<span class='splitline'>|</span> 豪华装修 </li>
问题解答
回答1:其实还是很有简单的,你看这个还是有规律的,规律在于有分隔符|,我写了个DEMO
something = ’’’<li><span class='info-tit'>房屋概况:</span>住宅 <span class='splitline'>|</span>1室1厅1卫<span class='splitline'>|</span><span>46m²</span><span class='splitline'>|</span> (高层)/共18层<span class='splitline'>|</span>南北<span class='splitline'>|</span> 豪华装修 </li>’’’;soup = BeautifulSoup(something, ’lxml’)plaintext = soup.select(’li’)[0].get_text().strip()
通过get_text()得到内在所有内容,然后去除空格。后面你就用split进行分割吧,后面的不写了。如果有问题再交流。
回答2:我感觉这个html代码写错了呢,标签的内容文本在标签外面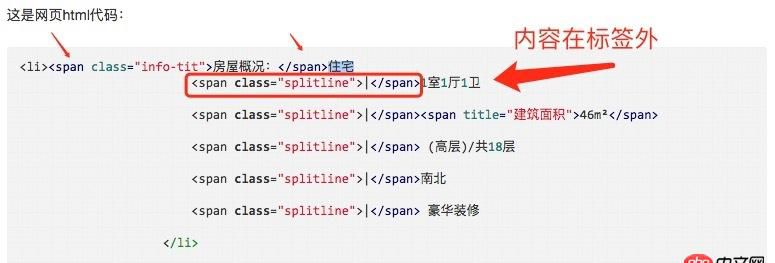
房屋概况:
46m²
回答3:innerText
回答4:你这种情况,我觉得用 for 循环加上正则表达式是最方便的,如果所有模版都是这样固定的话
回答5:用pyquery吧
from pyquery import PyQuery as Q
Q(text).find(’.house-info li’).text()
相关文章:
1. javascript - axios请求回来的数据组件无法进行绑定渲染2. 使用git管理webpack的代码时多人怎么协作?一般托管哪些文件?3. CSS3的渐变属性的疑惑4. javascript - 单个页面执行多个jsonp的ajax请求,如何判断一个ajax请求执行完毕执行再另一个?5. 微信端电子书翻页效果6. objective-c - iOS开发使用什么对html进行代码高亮7. vue.js - weex 没有背景图片属性怎么办?8. css - transform-origin 旋转参考点9. javascript - 使用原生ajax时,URL编码的问题10. php程序员工具箱装的mysql怎么删除啊
 网公网安备
网公网安备