文章详情页
python - 使用scrapy框架爬百度图片被墙
浏览:226日期:2022-06-30 14:19:37
问题描述
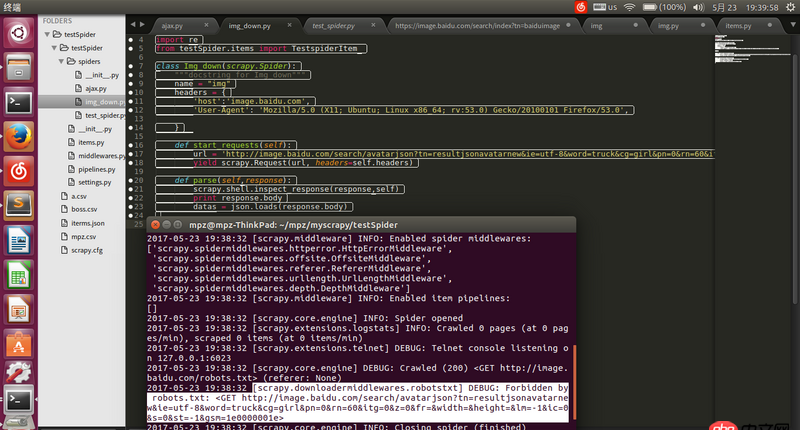
请求地址url是通过firefox查看得到的json的地址,用浏览器可以打开,但是用scrapy爬的时候就被ban了求解决办法。
https://image.baidu.com/searc...
问题解答
回答1:在 settings.py 将 ROBOTSTXT_OBEY = False 试试。
回答2:不要加hearders试试
回答3:赞成楼上,如果还会被墙。可采用scrapy+selenium+phantomjs的方式。
相关文章:
1. python for循环中的函数只能运行一次?2. 如何解决Centos下Docker服务启动无响应,且输入docker命令无响应?3. angular.js - angular ui bootstrap 中文显示问题4. javascript - table td单元格生成tr问题5. javascript - js读取excel其中一列中的一个值是0.3556但是读出来是0.35559999999999997?6. mysql5.7中group by和mysql5.5中group by的结果不一样7. html5 - h5页面在iphone上字体变形8. html - 竖线怎么实现9. 怎样写一个时间到了或是有订单的语音提醒呢?10. python - 使用pandas的resample报错
排行榜

 网公网安备
网公网安备