网页爬虫 - python 爬虫怎么处理json内容
问题描述
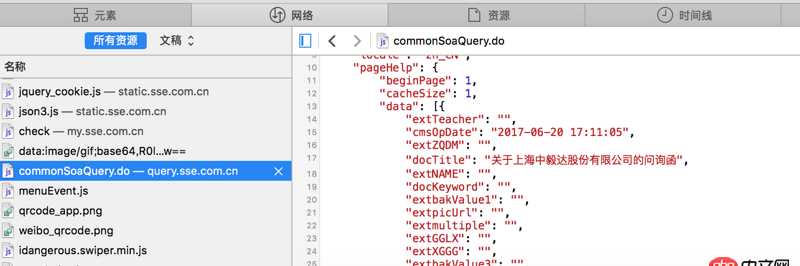
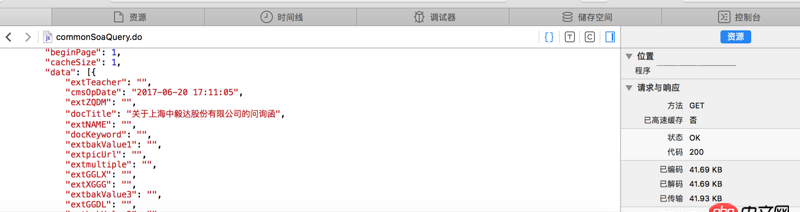
看不清的话 网站地址是http://www.sse.com.cn/disclos...红字是我需要的内容 但是我提取不出来求教怎么操作
问题解答
回答1:import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5’headers = { ’Referer’:’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’:’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’}r = requests.get(url, headers=headers)print r.json()[’result’]回答2:
import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382’session = requests.session()session.headers.update({ ’Referer’: ’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’})result = session.get(url).json()print result
相关文章:
1. html5 - iframe src可以引入其他域名或者IP吧iframe src可以是其他域名过IP吧2. javascript - 给js写的盒子添加css样式,css样式没起作用。3. javascript - 如何将psd裁切下来的图片非常清晰的宣示出来4. javascript - vuex中action应该怎么分发事件5. html5 - 请问一下写H5的时候 你们都是兼容那些手机6. html5 - ElementUI table中el-table-column怎么设置百分比显示。7. mysqli函数8. web前端页面中实现表格效果,这个表格是可编辑的9. javascript - h5页面中iframe无法唤起iOS应用?10. 数据挖掘 - 如何用python实现《多社交网络的影响力最大化问题分析》中的算法?
![php-_server-php_self - nginx $_SERVER[’PHP_SELF’] 得到重复路径是什么原因?](http://www.haobala.com/attached/image/news/202309/1123091c0c.png)
 网公网安备
网公网安备