文章详情页
python - 用sklearn求大文本的tfidf特征?
浏览:220日期:2022-06-27 15:50:07
问题描述
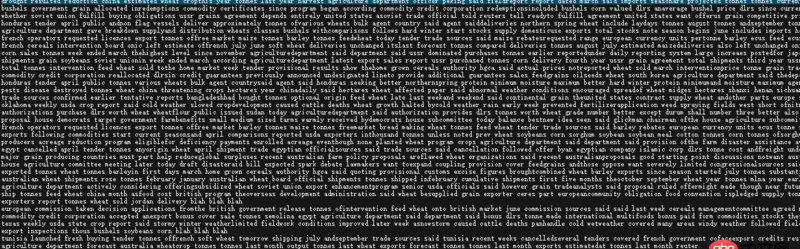 上面的数据是从reuters数据集中取得7303个训练集,用sklearn对其取tfidf特征,得到的结果都是0,这是怎么回事?
上面的数据是从reuters数据集中取得7303个训练集,用sklearn对其取tfidf特征,得到的结果都是0,这是怎么回事?
当我从这些数据中取一部分时,对于这些少部分数据能够得到正确的tfidf结果。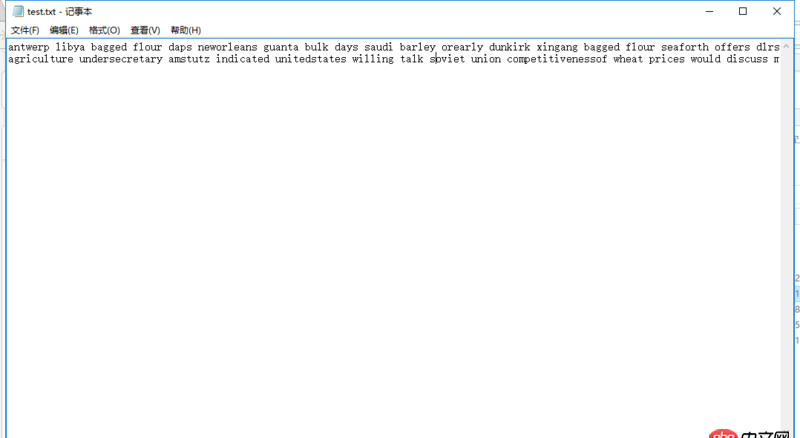

问题解答
回答1:上代码,可能是你精度太低或者min_count导致的
比如词频是1,总词数1e9,对应的tf就是1e-9,被忽略了。
相关文章:
1. font-family - 我引入CSS3自定义字体没有效果?2. dockerfile - 为什么docker容器启动不了?3. Docker for Mac 创建的dnsmasq容器连不上/不工作的问题4. docker内创建jenkins访问另一个容器下的服务器问题5. css - 如何讓圖片像雲一樣的行為?6. docker - 各位电脑上有多少个容器啊?容器一多,自己都搞混了,咋办呢?7. css3 - CSS优先级问题8. javascript - 网页打印页另存为pdf的代码一个问题9. docker镜像push报错10. nignx - docker内nginx 80端口被占用
排行榜
 网公网安备
网公网安备