网页爬虫 - python 爬取网站 并解析非json内容
问题描述
小弟刚学会获得json的内容,但今天爬的网站返回的并不是json内容 并且会有一个随机数的生成在每次请求链接的后面
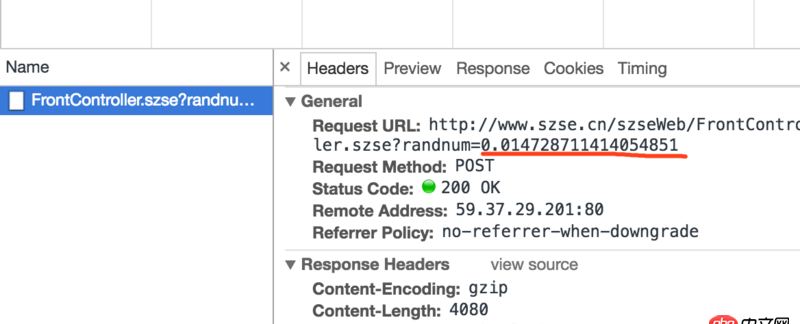
不知道会不会影响我要爬的内容
需要获得内容是下图中间的内容
 网站链接 http://www.szse.cn/main/discl...
网站链接 http://www.szse.cn/main/discl...
我自己尝试的代码:
import requestsdir = ’/Users/S1Lence/Desktop/new_html/szse/许可类重组问询函’headers = {’Host’: ’www.szse.cn’, ’Referer’: ’http://www.szse.cn/main/disclosure/jgxxgk/wxhj/’, ’User-Agent’: ’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36’ }payload= {’ACTIONID’: ’7’, ’AJAX’: ’AJAX-TRUE’, ’CATALOGID’: ’main_wxhj’, ’TABKEY’: ’tab1’, ’selecthjlb’: ’许可类重组问询函’, ’tab1PAGENO’: ’1’, ’tab1PAGECOUNT’: ’7’, ’tab1RECORDCOUNT’: ’63’, ’REPORT_ACTION’: ’navigate’}res = requests.post(’http://www.szse.cn/szseWeb/FrontControllere’, data=payload)print(res.text)
输出的内容并不是我想要的 求解应该怎么爬
问题解答
回答1:把他的header信息拷过来用。。
回答2:你post的url地址写错了,应该是
http://www.szse.cn/szseWeb/FrontController.szse
相关文章:
1. javascript - 微信小程序 如何实现这种左滑动出现删除的办法?有相关api吗?2. docker 17.03 怎么配置 registry mirror ?3. dockerfile - 为什么docker容器启动不了?4. 关docker hub上有些镜像的tag被标记““This image has vulnerabilities””5. python打开.py文件的时候出现window无法打开该文件是怎么回事呢?6. javascript - sublime快键键问题7. css - 图片的宽度发生变化而高度却没有相应变?8. docker gitlab 如何git clone?9. javascript - swiper插件loop模式下的BUG?10. javascript - vue中input的blur影响了下拉的点击事件如何解决

 网公网安备
网公网安备