JAVA实现DOC转PDF的示例代码
Word作为目前主流的文本编辑软件之一,功能十分强大,应用人群广,但是它也存在一些问题。像是Word文件在不同软件或操作平台之间传输的时候,时不时会出现各种格式的“变化”,也会有点“不稳定”,例如内容和格式经常容易篡动。
相较于Word,pdf格式文件显然优秀不少。虽然在内容编辑和修改方面表现不佳,但pdf格式文件在不同平台和软件上的稳定性表现着实出色。日常办公中,越来越多的会选择将编辑好的Word文件转换成Pdf格式文件,然后再分享给第三方浏览。
如果只是1个Word文件转换成Pdf文件,简直so easy;10个Word文件转换成pdf文件,虽烦躁,但能忍;如果是将1000个word文件转换成pdf文件呢?这会估计一股无名之火直冲天灵盖,立马想摔电脑的冲动都有了。
但对于程序猿来说,操作起来显然会容易很多,正好接到一个任务,索性就来和大家分享一下:将docx转成PDF文档,还要以代码的方式实现批量操作。先后参考了Apache poi java库以及docx4j组件,于是选择以docx4j组件来进行文档操作。
第一批次的文档共90篇:

以下开始实现docx4j的文档转PDF功能:
一、下载依赖docx4j所有的依赖jar包使用marven去处理还是蛮简洁的:
<dependency><groupId>org.docx4j</groupId><artifactId>docx4j-JAXB-Internal</artifactId><version>8.2.4</version></dependency><dependency><groupId>org.docx4j</groupId><artifactId>docx4j-export-fo</artifactId><version>8.2.4</version></dependency>
就两个,短暂等待下载依赖之后发现,docx4j的依赖jar包还是挺多的:
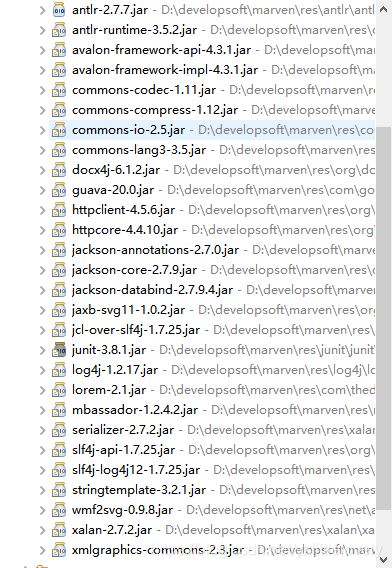
手动开始敲代码吧。
二、代码实现package com.convert.test;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import org.docx4j.Docx4J;import org.docx4j.fonts.IdentityPlusMapper;import org.docx4j.fonts.Mapper;import org.docx4j.fonts.PhysicalFonts;import org.docx4j.openpackaging.exceptions.Docx4JException;import org.docx4j.openpackaging.packages.WordprocessingMLPackage;public class ConvertTest {public static void main(String[] args) {word2pdf('D:tran2.doc', 'D:tran2.pdf');}public static void word2pdf(String source, String target) {try { WordprocessingMLPackage pkg = Docx4J.load(new File(source)); Mapper fontMapper = new IdentityPlusMapper(); fontMapper.put('隶书', PhysicalFonts.get('LiSu')); fontMapper.put('宋体', PhysicalFonts.get('SimSun')); fontMapper.put('微软雅黑', PhysicalFonts.get('Microsoft Yahei')); fontMapper.put('黑体', PhysicalFonts.get('SimHei')); fontMapper.put('楷体', PhysicalFonts.get('KaiTi')); fontMapper.put('新宋体', PhysicalFonts.get('NSimSun')); fontMapper.put('华文行楷', PhysicalFonts.get('STXingkai')); fontMapper.put('华文仿宋', PhysicalFonts.get('STFangsong')); fontMapper.put('仿宋', PhysicalFonts.get('FangSong')); fontMapper.put('幼圆', PhysicalFonts.get('YouYuan')); fontMapper.put('华文宋体', PhysicalFonts.get('STSong')); fontMapper.put('华文中宋', PhysicalFonts.get('STZhongsong')); fontMapper.put('等线', PhysicalFonts.get('SimSun')); fontMapper.put('等线 Light', PhysicalFonts.get('SimSun')); fontMapper.put('华文琥珀', PhysicalFonts.get('STHupo')); fontMapper.put('华文隶书', PhysicalFonts.get('STLiti')); fontMapper.put('华文新魏', PhysicalFonts.get('STXinwei')); fontMapper.put('华文彩云', PhysicalFonts.get('STCaiyun')); fontMapper.put('方正姚体', PhysicalFonts.get('FZYaoti')); fontMapper.put('方正舒体', PhysicalFonts.get('FZShuTi')); fontMapper.put('华文细黑', PhysicalFonts.get('STXihei')); fontMapper.put('宋体扩展', PhysicalFonts.get('simsun-extB')); fontMapper.put('仿宋_GB2312', PhysicalFonts.get('FangSong_GB2312')); fontMapper.put('新細明體', PhysicalFonts.get('SimSun')); pkg.setFontMapper(fontMapper); Docx4J.toPDF(pkg, new FileOutputStream(target));} catch (FileNotFoundException e) { e.printStackTrace();} catch (Docx4JException e) { e.printStackTrace();} catch (Exception e) { e.printStackTrace();}}}三、转换结果
SLF4J: Failed to load class 'org.slf4j.impl.StaticLoggerBinder'.SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.Using pdbs 420=7mmUsing pdbs 420=7mm
有一点报错,不过并不影响pdf的生成,打开生成的pdf,内容也是完整的。算是完成了吧,只要再写一个for循环,去遍历所有的文档就可以了。但是后来发现转换下来的pdf数量少了10个,所有的文档并没有全都转换成功。
四、后续研究排查一番,发现这些文档中有10个doc文档,就该就是这10个没有成功了,单独拎出来转换一下,结果就报错了:
SLF4J: Failed to load class 'org.slf4j.impl.StaticLoggerBinder'.SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.org.docx4j.openpackaging.exceptions.Docx4JException: This file seems to be a binary doc/ppt/xls, not an encrypted OLE2 file containing a doc/pptx/xlsxat org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:612)at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:414)at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:287)at org.docx4j.openpackaging.packages.OpcPackage.load(OpcPackage.java:265)at org.docx4j.openpackaging.packages.WordprocessingMLPackage.load(WordprocessingMLPackage.java:168)at org.docx4j.Docx4J.load(Docx4J.java:232)at com.convert.test.ConvertTest.word2pdf(ConvertTest.java:26)at com.convert.test.ConvertTest.main(ConvertTest.java:19)
This file seems to be a binary doc/ppt/xls, not an encrypted OLE2 file containing a doc/pptx/xlsx“此文件似乎是一个二进制文件doc/ppt/xls,而不是包含doc/pptx/xlsx的加密OLE2文件”貌似docx4j并不能完美的支持所有的word文档,至少doc文档并不能支持。我想到之前有小伙伴也遇到过这样问题,后来说是用了永中的office转换,索性今天自己也来尝试一下。
三下五除二,一顿操作,永中office官网上的office直接就能把我的doc文档转成html展示在浏览器上,心细如尘的我,还在其官网上发现有一款“PDF工具集”的产品:
在文章的右侧有“开发者”选项,可以直接点击它进入到转换的界面。进入之后,发现永中支持的格式还是不少的,在页面的上半部分就列出了当前支持的所有格式:

继续向下滚动鼠标滚轮,到达文档转换的位置:
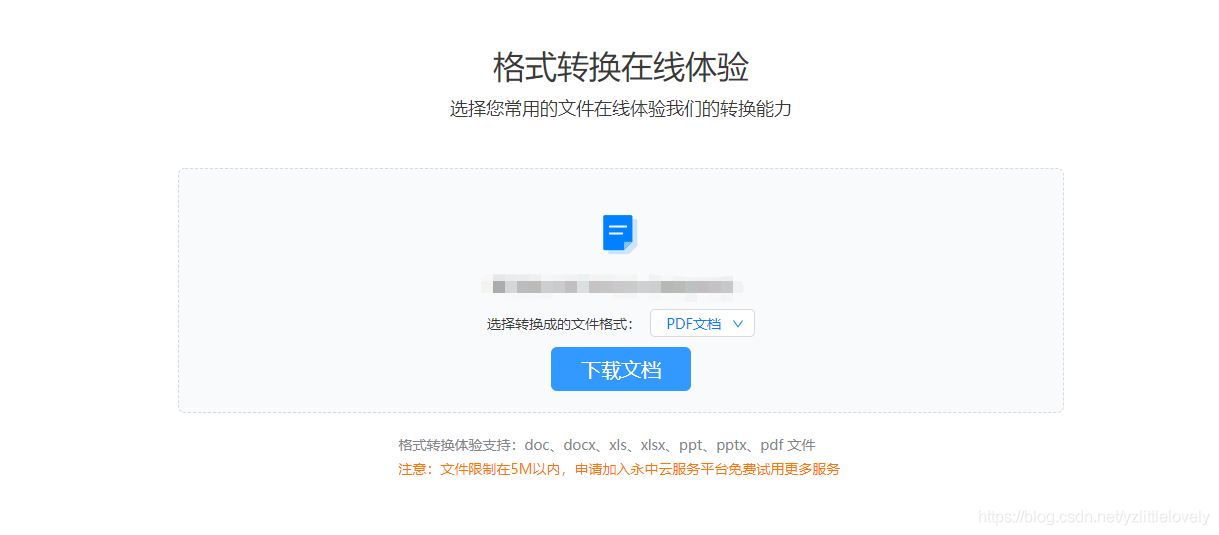
可以直接点击上传一份doc文档,等待上传完毕,就可以直接将doc文档转换成PDF文档了,这样一来,不管多少个文件,都能一键实现word文件转换成pdf文件,小伙伴们再也不用担心了。
五、总结其实,目前市面上已有的文档转换类的产品非常多,市场竞争十分激烈。但依旧不妨碍有好的产品涌现出来,受到一众用户的喜欢和追捧。
一款好的产品一定是契合用户的本性,能够对用户形成一种强大的吸引力,将其牢牢“粘住”。就像永中的这款产品,紧跟市场需求,更看到了用户的痛点,真正做到用一款简单、实用、好操作的产品,赢得市场,更赢得了用户!
到此这篇关于JAVA实现DOC转PDF的示例代码的文章就介绍到这了,更多相关JAVA实现DOC转PDF功能内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备